CrateDB has certain characteristics when describing its transactional guarantees: Atomicity and eventual consistency.
Atomicity on record-level guarantees that if a record is written to CrateDB, it either gets written as a whole or not at all. Eventual consistency refers to the effect that after ingesting records, those records are consistently available for querying only after a certain amount of time.
Although eventual consistency may sound like a limitation at first, it is part of an architecture decision that also brings advantages: Because indexing records is deferred, CrateDB can process data ingestion with minimal overhead and achieves high ingestion rates.
In this article, we will explain how eventual consistency works and outline strategies for how to handle it in client applications.
Ingestion workflow
To understand the inner workings behind eventual consistency, let’s look at the workflow that happens when new records are ingested. The workflow is on a shard level. If replication is used, each shard executes the workflow.
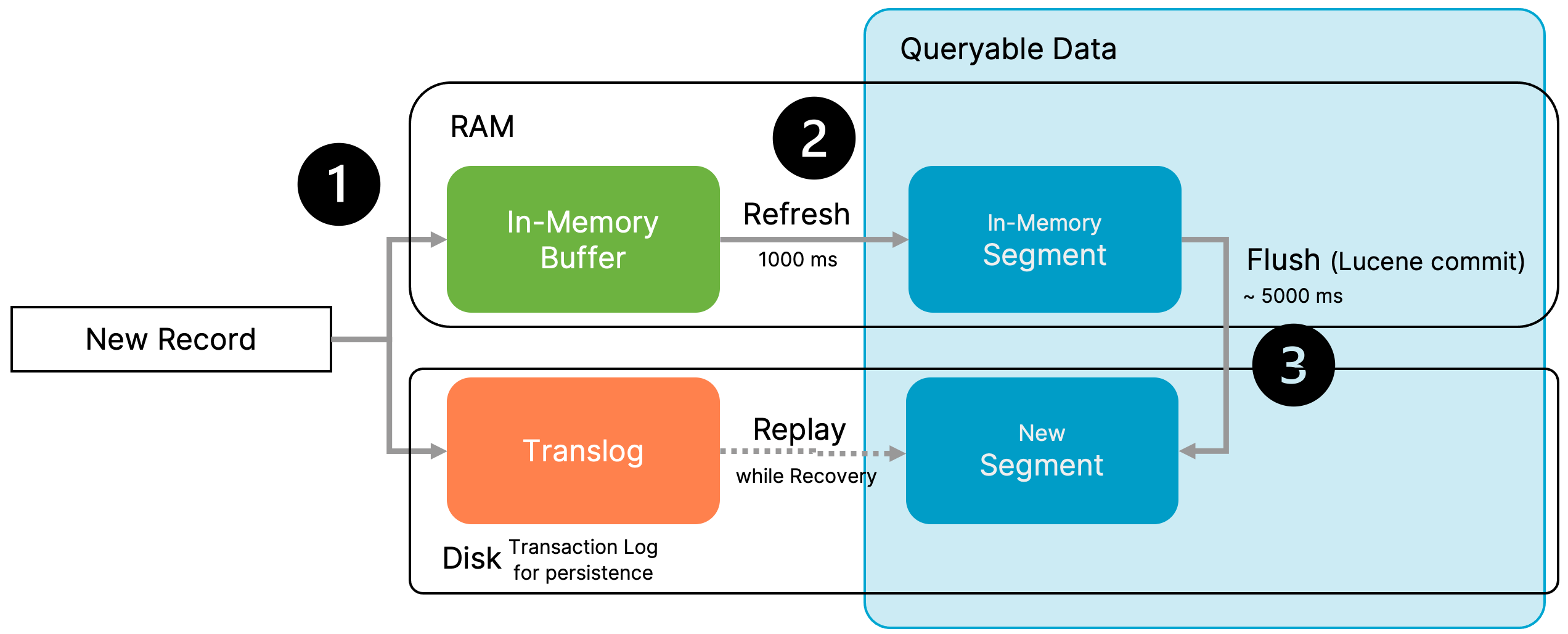
Once a record reaches a shard for ingestion, the following steps happen:
-
The record is written to an in-memory buffer. Records in that buffer are not indexed yet. Queries do not access the in-memory buffer and therefore its content will not be included in any result set.
At the same time, the record is also written to the translog on disk. The translog is used in recovery scenarios and also plays a special role in primary key lookups, as discussed later.
-
After a certain duration, all records that have accumulated in the in-memory buffer are indexed and transferred into an in-memory Lucene segment.
A segment is a fully independent index structure and enables data to be queried. The interval in which data is transferred from the in-memory buffer to an in-memory segment is referred to as the refresh interval and defaults to one second. -
A flush moves the in-memory segment to the disk. This flush has no impact on query behavior, but allows the translog to get purged.
The most noticeable impact on query behavior is the refresh interval. It describes the interval in which newly inserted records are indexed and therefore become consistently available for querying.
Once generated, segments are immutable. However, segments can be merged as part of an OPTIMIZE run to achieve optimal segment sizes.
Handling eventual consistency
A number of approaches allow influencing or mitigating eventual consistency to a certain degree.
Changing the refresh interval
The refresh interval is specified on a table or partition level (see CREATE TABLE). To speed up consistency, the refresh interval can be lowered.
The following statement creates a table with a lower-than-default refresh interval of 500 ms:
CREATE TABLE readings(
sensor_id INTEGER NOT NULL,
ts TIMESTAMP WITH TIME ZONE NOT NULL,
payload OBJECT(DYNAMIC),
PRIMARY KEY (sensor_id, ts)
)
WITH (refresh_interval = 500);
When not specifying a refresh interval explicitly during table creation, it defaults to one second. However, if a table is idle (table is not queried for more than 30 seconds), the refresh is deferred. It will then get executed as part of the first query that activates the table again.
Setting the refresh interval to 0 does not disable the refresh mechanism. Instead, CrateDB will decide when to refresh data on other internal, non-time-based, factors.
ALTER TABLE also allows changing the refresh interval for existing tables or partitions: ALTER TABLE readings SET (refresh_interval = 1000);.
Changing the refresh interval has performance implications: Transferring data from the in-memory buffer to an in-memory segment consumes CPU cycles. The subsequent flush to disk causes write operations to disk. Lowering or increasing the refresh interval directly impacts the frequency of those operations.
Increasing the refresh interval can be relevant in high-load ingest scenarios. By running the refresh less often, more CPU cycles are available for indexing and fewer small segments get produced that need to be merged later on.
Manual table refresh
Instead of waiting for the period refresh to happen, the REFRESH command allows triggering it manually:
REFRESH TABLE readings;
Refreshing a table manually can be useful in two scenarios:
- After ingestion of certain data to ensure newly inserted rows are consistently available to all subsequent queries.
- Before running a
SELECTquery to ensure all records stored in CrateDB prior to running theREFRESH TABLEcommand are available for querying.
REFRESH TABLE can also run on specific partitions only, if specified.
Querying by primary key
One exception to the described refresh mechanism is to perform a lookup by the primary key. In our example, this could be a query such as:
SELECT *
FROM readings
WHERE sensor_id = 5
AND ts = '2022-09-25 19:00:00';
Querying by primary key performs an additional lookup on the translog, making it independent of the refresh interval.
For this to work, you need to perform an exact lookup. A WHERE clause with a range query such as WHERE sensor_id >= 5 AND ts >= '2022-09-25 19:00:00' will not be served by the translog. See REFRESH — CrateDB: Reference for more details.
Using the RETURNING clause on INSERT statements
In some scenarios, tables might not have well-defined primary keys. CrateDB implicitly adds an _id column to each row for all tables. The value for _id uniquely identifies a row within a table. If a primary key is defined, _id is derived from its value. Lookups by _id are also served from the translog:
cr> INSERT INTO readings VALUES (1, NOW(), {value=5}) RETURNING _id;
+--------------------------+
| _id |
+--------------------------+
| AgExDTE2NjQxOTY0NTMxNTI= |
+--------------------------+
INSERT 1 row in set (0.038 sec)
cr> SELECT * FROM readings WHERE _id = 'AgExDTE2NjQxOTY0NTMxNTI=';
+-----------+---------------+--------------+
| sensor_id | ts | payload |
+-----------+---------------+--------------+
| 1 | 1664196453152 | {"value": 5} |
+-----------+---------------+--------------+
SELECT 1 row in set (0.039 sec)
Note: In certain CrateDB versions, lookup by _id was not functioning correctly for tables with an explicit primary key definition. A fix will be released with CrateDB 5.0.2.
Summary
Eventual consistency is a particularity that only concerns newly ingested data within the last one second (by default). The discussed approaches allow mitigating the effects to some degree. Nevertheless, eventual consistency is one of CrateDB’s core architecture principles that cannot be circumvented entirely.
For additional transaction-related aspects of CrateDB, also check out Optimistic Concurrency Control — CrateDB: Reference.