There is an updated version of this tutorial on Updating stock market data automatically with CrateDB and Apache Airflow
Motivation
Previously, on the Automating financial data collection and storage in CrateDB with Python and pandas 2.0.0 post in CrateDB’s community, I wrote a step-by-step tutorial on how to get stock market data from S&P-500 companies and store them in CrateDB using Jupyter Notebook.
Although Jupyter is a great environment for prototyping, where I can get instant code evaluations and easily plot data, it’s not production efficient due to difficult unit testing, no proper dependency management, and no code versioning, among others.
Airflow, on the other hand, is widely used in production, runs Python code, allows code versioning, and I can easily track the execution of my tasks in their user-friendly UI. So, in this tutorial, I will demonstrate how to adapt the Python code I already had on Jupyter to run as an Airflow DAG.
This post will show how to:
- write Python functions as Airflow tasks
- create a DAG
- run a DAG in Airflow
The complete DAG, as well as installing and starting instructions, can be found in our GitHub repository.

Setup
This blog post is part of the CrateDB and Apache Airflow series, a series with various use cases of Airflow and CrateDB. If you are interested in learning more about Airflow, Astronomer, and getting more detailed setup steps, head to the first post CrateDB and Apache Airflow: Automating Data Export to S3, which was the foundation for this tutorial.
I follow the tutorial mentioned above and have both CrateDB and Airflow up and running. Now I can head for the next steps and create Airflow tasks.
Tasks
This is a high-level explanation of the tasks. If you wish to know more about the logic behind them, the previous tutorial has an in-depth explanation of each of the functions used in this section.
I can divide my script into the following tasks:
- Download financial data from Yahoo
- Prepare the data
- Format and insert data into CrateDB
And I go through each one of them separately:
Download financial data
In the get_sp500_ticker_symbols function, I get the ticker symbols from the List of S&P-500 companies and return them.
In download_yfinance_data, I get these ticker symbols, download the Adjusted Close data for each of them using the yfinance API and return it as a JSON object.
@task(execution_timeout=datetime.timedelta(minutes=3))
def download_yfinance_data(ds=None):
"""Downloads Adjusted Close data from S&P 500 companies"""
tickers = get_sp500_ticker_symbols()
data = yf.download(tickers, start=ds)['Adj Close']
return data.to_json()
@task(execution_timeout=datetime.timedelta(minutes=3))
def prepare_data(string_data):
"""Creates a list of dictionaries with clean data values"""
# transforming to dataframe for easier manipulation
df = pd.DataFrame.from_dict(json.loads(string_data), orient='index')
values_dict = []
for col, closing_date in enumerate(df.columns):
for row, ticker in enumerate(df.index):
adj_close = df.iloc[row, col]
if not(adj_close is None or math.isnan(adj_close)):
values_dict.append(
{'closing_date': closing_date, 'ticker': ticker, 'adj_close': adj_close}
)
else:
logging.info("Skipping %s for %s, invalid adj_close (%s)",
ticker, closing_date, adj_close)
return values_dict
Prepare the data
In prepare_data, I now take the raw JSON data returned from the yfinance API, clean it, turn each company’s data into a dictionary of values, and store it in a list of dictionaries values_dict.
@task(execution_timeout=datetime.timedelta(minutes=3))
def prepare_data(string_data):
"""Creates a list of dictionaries with clean data values"""
# transforming to dataframe for easier manipulation
df = pd.DataFrame.from_dict(json.loads(string_data), orient='index')
values_dict = []
for col, closing_date in enumerate(df.columns):
for row, ticker in enumerate(df.index):
adj_close = df.iloc[row, col]
if not(adj_close is None or math.isnan(adj_close)):
values_dict.append(
{'closing_date': closing_date, 'ticker': ticker, 'adj_close': adj_close}
)
else:
logging.info("Skipping %s for %s, invalid adj_close (%s)",
ticker, closing_date, adj_close)
return values_dict
Format and insert data into CrateDB
Finally, I put it all together by defining the main execution method financial_data_import. It defines dependencies between tasks and passes data between tasks. A PostgresOperator is then used to execute individual SQL statements for each row. The expand method is part of Airflows’ dynamic task mapping and calles the PostgresOperator for each value in by prepared_data.
def financial_data_import():
yfinance_data = download_yfinance_data()
prepared_data = prepare_data(yfinance_data)
PostgresOperator.partial(
task_id="insert_data_task",
postgres_conn_id="cratedb_connection",
sql="""
INSERT INTO doc.sp500 (closing_date, ticker, adjusted_close)
VALUES (%(closing_date)s, %(ticker)s, %(adj_close)s)
ON CONFLICT (closing_date, ticker) DO UPDATE SET adjusted_close = excluded.adjusted_close
""",
).expand(parameters=prepared_data)
Now that I have gone through the functions, it’s time to finally create the Airflow DAG.
Create the DAG
I must gather these functions into theDAG structure for Airflow.
Inside the dags folder in my project, I add a financial_data_dag.py file with the following structure:
- Import operators
- Import Python modules
- Declare functions
- Set DAG and its tasks
As a prerequisite to insert data, the table sp500 must be manually created (once) in CrateDB.
"""
Downloads stock market data from S&P 500 companies and inserts it into CrateDB.
Prerequisites
-------------
In CrateDB, the schema to store this data needs to be created once manually.
See the file setup/financial_data_schema.sql in this repository.
"""
import datetime
import math
import json
import logging
import pendulum
import requests
from bs4 import BeautifulSoup
import yfinance as yf
import pandas as pd
from airflow.providers.postgres.operators.postgres import PostgresOperator
from airflow.decorators import dag, task
"""
get_sp500_ticker_symbols():
download_yfinance_data(ds):
prepare_data_function(string_data):
"""
@dag(
start_date=pendulum.datetime(2022, 1, 10, tz="UTC"),
schedule_interval="@daily",
catchup=False,
)
def financial_data_import():
yfinance_data = download_yfinance_data()
prepared_data = prepare_data(yfinance_data)
PostgresOperator.partial(
task_id="insert_data_task",
postgres_conn_id="cratedb_connection",
sql="""
INSERT INTO doc.sp500 (closing_date, ticker, adjusted_close)
VALUES (%(closing_date)s, %(ticker)s, %(adj_close)s)
ON CONFLICT (closing_date, ticker) DO UPDATE SET adjusted_close = excluded.adjusted_close
""",
).expand(parameters=prepared_data)
financial_data_dag = financial_data_import()
Run DAG in Airflow
With the financial_data_dag.py all set, I save it and see it in the Airflow UI.

I click on the start button in the right corner to trigger the DAG and click on the Last Run to follow the execution
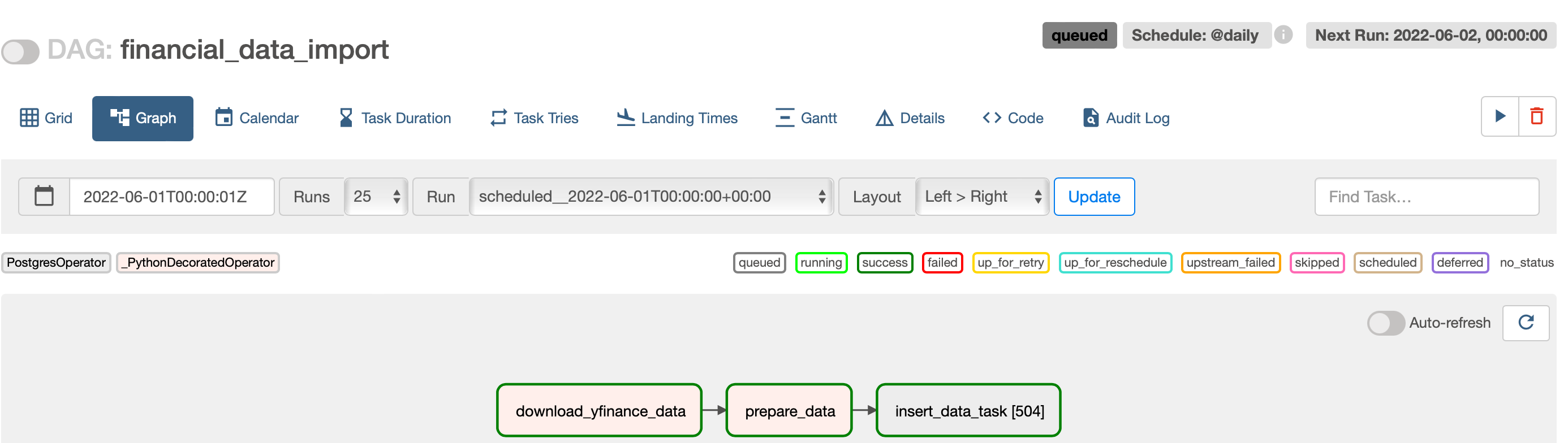
This shows the DAG has been executed without errors.
I navigate to the CrateDB Admin UI to check whether the data was inserted, and I see my sp500 table is already filled with data:

I make an easy query to get some companies’ data with
SELECT *
FROM sp500
WHERE ticker = 'AAPL'
LIMIT 100;

And I get the historical stock data instantly!