You may have line-of-business applications such as ERP software that work with transactional database systems like MSSQL, Oracle, or MySQL.
The setup may work perfectly fine for day-to-day operations, but you may find that it is not ideal for doing data analytics.
Attempting to run analytic workloads against the operational databases you may see concurrency issues deriving from locking, the analytics queries may have an impact on the performance of business-critical operations, and you may also find that the performance and feature-set in the transactional database system may not be good enough for analyzing large amounts of data.
Considering this, many organisations come to the conclusion they need to copy data to a separate environment to run reporting and dashboards, this is sometimes done with replication, sometimes with backups, and sometimes with complex ETL pipelines. This often comes with a set of challenges:
- ballooning license costs
- custom ad-hoc routines for getting the data to the analytics environment, requiring development, monitoring, and troubleshooting
- a need to design and maintain an indexing strategy for the analytics copy of the data
- high availability requirements for the analytics environment as the business starts relying on it
We know we can address several of these points by using a system like CrateDB. CrateDB is a feature-rich, open-source, SQL database which out-of-the-box automatically implements indexes, compression, and a columnar store so that most analytical queries can run much faster without any need to fiddle with settings. Because it is open-source, there is no need to be concerned about licensing expenses. Additionally, it can scale horizontally, which means that the number of nodes can be adjusted as needed to handle changing data volumes and workloads, and it provides high availability without requiring administrative effort.
If only we could replicate data from our operational database to CrateDB without having to write custom code… it turns out we can.
Enter Debezium, Debezium is a standard open-source system, built on top of Kafka, which allows to capture changes on a source database system and replicate them on another system without having to write custom scripts.
In this post I want to show an example replicating changes on a table from MSSQL to CrateDB.
Setup on the MSSQL side
We will need a SQL Server instance with the SQL Server Agent service up and running, if you are running MSSQL on a container you can get the agent running by setting the environment variable MSSQL_AGENT_ENABLED to True.
Connect to the instance with a client such as sqlcmd, SSMS, or DBeaver.
We are now going to go through a number of steps, if you already have a working system feel free to skip the operations you do not need.
Let’s create a database with a test table on it:
CREATE DATABASE erp;
GO
USE erp;
CREATE TABLE dbo.tbltest (
id INT PRIMARY KEY IDENTITY,
createdon DATETIME DEFAULT getdate(),
srcsystem NVARCHAR(max)
);
Let’s now create an account for Debezium to use to pull the changes:
CREATE LOGIN debeziumlogin WITH PASSWORD = '<enterStrongPasswordHere>';
CREATE USER debeziumuser FOR LOGIN debeziumlogin;
CREATE ROLE debeziumrole;
EXEC sp_addrolemember 'debeziumrole', 'debeziumuser';
EXEC sp_addrolemember 'db_datareader', 'debeziumuser';
And let’s enable change data capture on our example table:
EXEC sys.sp_cdc_enable_db;
ALTER DATABASE erp ADD FILEGROUP cdcfg;
ALTER DATABASE erp ADD FILE (
NAME= erp_cdc_file1,
FILENAME='/var/opt/mssql/data/erp_cdc_file1.ndf'
) TO FILEGROUP cdcfg;
EXEC sys.sp_cdc_enable_table
@source_schema='dbo',
@source_name='tbltest',
@role_name='debeziumrole',
@filegroup_name='cdcfg',
@supports_net_changes=0;
Setup on the CrateDB side
We will need a CrateDB instance, for the purpose of this example we can spin one up with:
sudo apt install docker.io
sudo docker run --publish 4200:4200 --publish 5432:5432 --env CRATE_HEAP_SIZE=1g crate:latest -Cdiscovery.type=single-node
Now we need to run a couple of SQL commands on this instance, an easy way to do this is using the Admin UI that can be accessed navigating with a web browser to port 4200 on the server where CrateDB is running, for instance http://localhost:4200 and then open the console (second icon from the top on the left-hand side navigation bar).
We will create a user account for Debezium to use:
CREATE USER debezium WITH (password='debeziumpwdincratedb123');
The table on our MSSQL source is on the dbo schema, let’s imagine we want to have a dbo schema on CrateDB as well, the debezium account will need permissions on it:
GRANT DQL,DML,DDL ON SCHEMA dbo to debezium;
And let’s create the structure of the table that will receive the data:
CREATE TABLE dbo.tbltest (
id INT PRIMARY KEY /* we need the PK definition to match the source table so that this can be used to lookup records when they need to be updated */
,createdon TIMESTAMP /* CrateDB supports defaults -of course- but because the source table already has a default value we do not need that here */
,srcsystem TEXT
);
Zookeeper and Kafka
To use Debezium we will need to have working setups of Zookeeper and Kafka.
For the purpose of this example I will spin them up with containers on the same machine:
sudo docker run -it --rm --name zookeeper -p 2181:2181 -p 2888:2888 -p 3888:3888 debezium/zookeeper
sudo docker run -it --rm --name kafka -p 9092:9092 --link zookeeper:zookeeper --add-host host.docker.internal:host-gateway debezium/kafka
We need to create some special topics in Kafka:
sudo docker exec -it kafka "bash"
bin/kafka-topics.sh --create --replication-factor 1 --partitions 1 --topic my_connect_configs --bootstrap-server host.docker.internal:9092 --config cleanup.policy=compact
bin/kafka-topics.sh --create --replication-factor 1 --partitions 1 --topic my_connect_offsets --bootstrap-server host.docker.internal:9092 --config cleanup.policy=compact
exit
Please note this is a very basic setup, for production purposes you may want to adjust some of these settings.
Preparing and starting a Debezium container image
We need to customize the base debezium/connect Docker image adding a JDBC sink and the PostgreSQL drivers.
For this we need to download the zip file from kafka-connect-jdbc and then run the below replacing ************* with the appropriate URL:
mkdir customdockerimg
cd customdockerimg
wget *************/confluentinc-kafka-connect-jdbc-10.6.3.zip
sudo apt install unzip
mkdir confluentinc-kafka-connect-jdbc-10.6.3
cd confluentinc-kafka-connect-jdbc-10.6.3
unzip -j ../confluentinc-kafka-connect-jdbc-10.6.3.zip
cd ..
cat > Dockerfile <<EOF
FROM debezium/connect
USER root:root
COPY ./confluentinc-kafka-connect-jdbc-10.6.3/ /kafka/connect/
RUN cd /kafka/libs && curl -sO https://jdbc.postgresql.org/download/postgresql-42.5.4.jar
USER 1001
EOF
sudo docker build -t cratedb-connect-debezium .
Let’s now start this custom image:
sudo docker run -it --rm --name connect -p 8083:8083 \
-e GROUP_ID=1 \
-e CONFIG_STORAGE_TOPIC=my_connect_configs \
-e OFFSET_STORAGE_TOPIC=my_connect_offsets \
--add-host host.docker.internal:host-gateway \
--add-host $(hostname):host-gateway \
-e BOOTSTRAP_SERVERS=host.docker.internal:9092 \
-e KEY_CONVERTER=org.apache.kafka.connect.json.JsonConverter \
-e VALUE_CONVERTER=org.apache.kafka.connect.json.JsonConverter \
cratedb-connect-debezium
This assumes Kafka is running locally on the same server, you will need to adjust BOOTSTRAP_SERVERS if that is not the case.
Configure a source connector
Let’s create a connector.json file as follows:
{
"name": "mssql-source-tbltest",
"config": {
"connector.class": "io.debezium.connector.sqlserver.SqlServerConnector",
"tasks.max": "1",
"database.history.kafka.bootstrap.servers": "host.docker.internal:9092",
"schema.history.internal.kafka.bootstrap.servers": "host.docker.internal:9092",
"topic.prefix": "cratedbdemo",
"database.encrypt": "false",
"database.hostname": "host.docker.internal",
"database.port": "1433",
"database.user": "debeziumlogin",
"database.password": "<enterStrongPasswordHere>",
"database.server.name": "mssql-server",
"database.names": "erp",
"table.whitelist": "dbo.tbltest",
"database.history.kafka.topic": "schema-changes.mssql-server.tbltest",
"schema.history.internal.kafka.topic": "schema-changes.inventory.mssql-server.tbltest"
}
}
We can observe that there are settings there concerning the Kafka setup to use, the details to connect to MSSQL, the name of the table that we want to pull changes from, and the Kafka topics that will be used to track these changes.
Let’s deploy this:
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @connector.json
Configure a target
Let’s create a destination-connector.json file as follows:
{
"name": "cratedb-sink-tbltest",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"connection.url": "jdbc:postgresql://host.docker.internal:5432/",
"connection.user": "debezium",
"connection.password": "debeziumpwdincratedb123",
"topics": "cratedbdemo.erp.dbo.tbltest",
"table.name.format": "dbo.tbltest",
"auto.create": "false",
"auto.evolve": "false",
"insert.mode": "upsert",
"pk.fields": "id",
"pk.mode": "record_value",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState"
}
}
We got details to connect to CrateDB, the name of table that will receive the changes (please note this is case sensitive), and some transform instructions to flatten the JSON data stored in the Kafka topic.
Let’s deploy this:
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @destination-connector.json
Testing
Let’s see this in action.
Let’s create a record from the MSSQL side:
INSERT INTO erp.dbo.tbltest (srcsystem) VALUES (@@version);
And now let’s go to CrateDB and check the table:
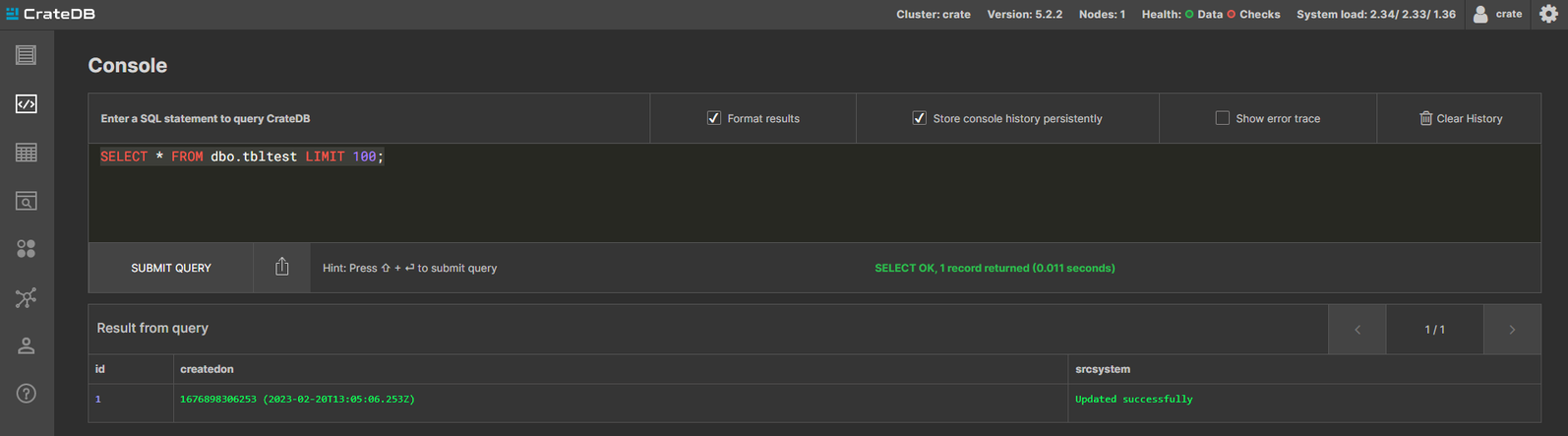
SELECT * FROM dbo.tbltest;
As magic the record is there.
Let’s now try an update from the MSSQL side:
UPDATE erp.dbo.tbltest
SET srcsystem = 'Updated successfully'
WHERE id = 1
Conclusion
Using Debezium we can replicate changes from different database systems to CrateDB without having to develop any custom logic, we can then take advantage of CrateDB’s performance and features for our analytic workloads.